Mindmap-Galerie Autonomic Nervous System (ANS) Drugs
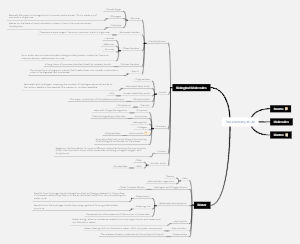
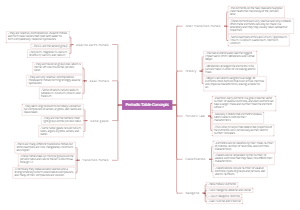
Autonomic Nervous System (ANS) Drugs
This is a mind map talking about the Autonomic Nervous System (ANS) Drugs. You can create a mind map like this effortlessly.
Bearbeitet um 2020-09-28 07:54:18- Creative Halloween Costume Ideas
Halloween has many faces. The theme you envision should influence how you decorate the party space. Jack-o'-lanterns and friendly ghosts are more lighthearted Halloween characters. Zombies, witches, and vampires are much darker. If you want to celebrate all the fun sides of Halloween, then it’s okay to mesh the cute with the frightening. Here is a mind map which lists down the 39 Cutest Couples Halloween Costumes of 2021.
- 35 Best and Classic Halloween Movies
Halloween simply wouldn't be Halloween without the movies that go along with it. There's nothing like a movie night filled with all the greatest chainsaw-wielding, spell-binding, hair-raising flicks to get you in the spooky season spirit. So, break out the stash of extra candy, turn off all the lights, lock every last door, and settle in for the best of the best Halloween movies. Here are the 35 Halloween movies listed on the mind map based on the year of release.
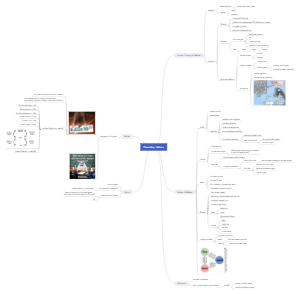
- Halloween Party Ideas Mind Map
This mind map contains lots of interesting Halloween trivia, great tips for costumes and parties (including food, music, and drinks) and much more. It talks about the perfect Halloween night. Each step has been broken down into smaller steps to understand and plan better. Anybody can understand this Halloween mind map just by looking at it. It gives us full story of what is planned and how it is executed.
Autonomic Nervous System (ANS) Drugs
- Creative Halloween Costume Ideas
Halloween has many faces. The theme you envision should influence how you decorate the party space. Jack-o'-lanterns and friendly ghosts are more lighthearted Halloween characters. Zombies, witches, and vampires are much darker. If you want to celebrate all the fun sides of Halloween, then it’s okay to mesh the cute with the frightening. Here is a mind map which lists down the 39 Cutest Couples Halloween Costumes of 2021.
- 35 Best and Classic Halloween Movies
Halloween simply wouldn't be Halloween without the movies that go along with it. There's nothing like a movie night filled with all the greatest chainsaw-wielding, spell-binding, hair-raising flicks to get you in the spooky season spirit. So, break out the stash of extra candy, turn off all the lights, lock every last door, and settle in for the best of the best Halloween movies. Here are the 35 Halloween movies listed on the mind map based on the year of release.
- Halloween Party Ideas Mind Map
This mind map contains lots of interesting Halloween trivia, great tips for costumes and parties (including food, music, and drinks) and much more. It talks about the perfect Halloween night. Each step has been broken down into smaller steps to understand and plan better. Anybody can understand this Halloween mind map just by looking at it. It gives us full story of what is planned and how it is executed.
- Für Sie empfohlen
- Gliederung